MLHandler provides ML APIs
MLHandler exposes machine learning models that applications can use over a REST API. (From v1.67.) It allows users to:
- create models from scratch, and iterate upon them,
- start with existing scikit-learn models, and evolve them.
Creating New Models
To train a new model on, say, the Titanic dataset, from scratch, use the following configuration:
url:
mlhandler-tutorial:
pattern: /$YAMLURL/ml
handler: MLHandler
kwargs:
data:
url: $YAMLPATH/titanic.csv # Path to the training dataset
# Path where the serialized model, training data and configuration is
# saved
config_dir: $YAMLPATH
model:
# The classification or regression algorithm to use
class: LogisticRegression
# The column to predict
target_col: Survived
# Columns to ignore during training
exclude: [PassengerId, Ticket, Cabin, Name]
# Columns to be treated as categorical variables
cats: [Embarked, SibSp, Parch, Pclass, Sex]
MLHandler will then,
- instantiate a LogisticRegression model
- load the training data as a Pandas DataFrame
- drop the excluded columns
- one-hot encode the categorical columns and normalize any remaining columns - which are implicitly assumed to be numerical.
- train the model and save it.
Other kwargs.model parameters that are supported are:
include: List of columns to include for training. Ifincludeandexcludeare both specified,includeoverridesexclude.nums: List of numerical features. All numerical features are normalized to have zero mean and unit variance, with StandardScaler.dropna: Whether to drop NAs from the training data - true by default. If set to false, sklearn may misbehave.deduplicate: Whether to drop duplicates from the training data - true by default. If set to false, training may be slower.
Note that all kwargs in MLHandler are optional. Any option can be specified at a later time with a PUT or a POST request. For example:
- If the model class and
datakwargs are not specified, MLHandler will do no training - which can be explicitly triggered at a later time, after supplying data and the algorithm (more on this below). - Any of the remaining kwargs can be specified before training begins.
config_dir is the directory where the model, data, and configuration are stored. It has 3 files:
config.json: Model parameters & configurationdata.h5: Training datamodel.pkl: The actual model, serialized as a Pickle file
config_dir defaults to $GRAMEXDATA/apps/mlhandler/<handler-key>/, where <handler-key> is the handler name, e.g. mlhandler-tutorial in the example above.
Exposing Existing Models
Existing scikit-learn models can be exposed with the MLHandler.
You can download a sample logistic regression model, trained on the Titanic dataset. The model is trained to predict if a passenger would have survived the Titanic disaster, given attributes of the passenger like age, gender, travel class, etc. The model can then be exposed in a Gramex application as follows:
url:
mymodel:
pattern: /$YAMLURL/model
handler: MLHandler
kwargs:
config_dir: $YAMLPATH
Model operations
Getting predictions
MLHandler allows getting predictions for a single data point through a simple curl -X GET request, as follows:
# See whether a 22 year old male, traveling with a sibling in the third class,
# having embarked in Southampton is likely to have survived.
curl -X GET /model?Sex=male&Age=22&SibSp=1&Parch=0&Fare=7.25&Pclass=3&Embarked=S
# output: [0] - passenger did not survive
>>> import requests
>>> requests.get('mlhandler?Sex=male&Age=22&SibSp=1&Parch=0&Fare=7.25&Pclass=3&Embarked=S')
$.ajax({
url: 'mlhandler?Sex=male&Age=22&SibSp=1&Parch=0&Fare=7.25&Pclass=3&Embarked=S',
method: 'GET'
})
curl -X GET mlhandler?Sex=male&Age=22&SibSp=1&Parch=0&Fare=7.25&Pclass=3&Embarked=S'
Note that the URL parameters in the GET query are expected to be fields in the training dataset, and can be passed as Python dictionaries or JS objects.
Getting bulk predictions
Predictions for a dataset (as against a single data point) can be retrieved by
POSTing a JSON dataset in the request body. The Titanic dataset is available
here without the target column, which you can use to
run the following example:
curl -X POST -d @titanic_predict.json http://localhost:9988/mlhandler?_action=predict
# Output: [0, 1, 0, 0, 1, ...] # whether each passenger is likely to have survived
>>> import requests
>>> requests.post('mlhandler?_action=predict', files={'file': open('titanic.xlsx', 'rb')})
$.ajax({
url: 'mlhandler?_action=predict',
method: 'POST',
data: new FormData(this),
processData: false,
contentType: false
})
curl -X POST -d @titanic.xlsx 'mlhandler?_action=predict'
Retraining the model
An existing model can be retrained by POSTing data and specifying a target column. To do so, we need to:
- post the training data as JSON records,
- set
?_action=retrainand perform a PUT, - set
?target_col=NEW_TARGET_COL, if required.
You can use the JSON dataset here to train the model as follows:
curl -X POST -d @titanic.json /mlhandler?_action=retrain&target_col=Survived
# Output: {'score': 0.80} - the model has 80% accuracy on the training data.
>>> import requests
>>> requests.post('mlhandler?_action=retrain&target_col=Survived',
files={'file': open('titanic.csv', 'rb')})
$.ajax({
url: 'mlhandler?_action=retrain&target_col=Survived',
method: 'POST',
data: new FormData(this),
processData: false,
contentType: false
})
curl -X POST -d @titanic.csv 'mlhandler?_action=retrain&target_col=Survived'
See model parameters
The parameters of a scikit-learn model can be obtained by specify the ?_model parameter,
as follows:
curl -X GET /mlhandler?_model
# Output
{
"params":
{
'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 100,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': None,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0,
'warm_start': False
},
"model": "LogisticRegression"
}
>>> import requests
>>> requests.get('mlhandler?_model).json()
{
"params":
{
'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 100,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': None,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0,
'warm_start': False
},
"model": "LogisticRegression"
}
$.getJSON('mlhandler?_model')
curl -X GET -d @titanic.csv 'mlhandler?_model'
Change the model and modify its parameters
An existing model can be replaced with a new one, and all its parameters can be modified with a PUT request. The following request replaces the logistic regression earlier with a random forest classifier:
curl -X PUT '/mlhandler?_model&class=RandomForestClassififer'
Note that at this stage, the model has simply been replaced, but not
retrained. To train it, we can POST to it with ?_action=retrain parameter as
follows:
curl -X POST '/mlhandler?_action=retrain'
Similarly, any parameter of the model can be changed. For example, to change the number of estimators used in a random forest classifier (which is 100, by default), use:
curl -X PUT /mlhandler?_model&n_estimators=10
In general, the model’s class and any of its parameters can be chained together in the PUT request. For example, to change the model to an SGDClassifier with a log loss, use:
curl -X PUT /mlhandler?_model&class=SGDClassifier&loss=log
Any query parameter except class which is also a parameter of the
SGDClassifier will be used to create the model.
Similarly, any of the data transformation options (include, exclude,
cats, nums, etc) can be added or changed at any time with a PUT, as follows:
# Ignore PassengerId and Name, consider Embarked as a categorical feature.
curl -X PUT /mlhandler?_model&exclude=PassengerId&exclude=Name&cats=Embarked
Delete a model
To remove the serialized model from the disk and disable further operations, use a delete request as follows:
curl -X DELETE /mlhandler?_model
MLHandler Templates
MLHandler supports Tornado templates which can be used to create front-end applications which use MLHandler. You can specify a template kwarg as follows:
mlhandler-tutorial:
pattern: /$YAMLURL/ml
handler: MLHandler
template: $YAMLPATH/template.html
The template so specified will be rendered at the pattern URL, and it will
have access to the following variables:
{{ handler }}: The MLHandler instance{{ handler.model }}: The sklearn object / estimator / model{{ data }}: The training dataset, available as a Pandas DataFrame.
{{ handler.model }} gives you access to the underlying sklearn object. This can
be used in many ways to replicate sklearn code. For example,
- Use
{{ handler.model.get_params() }}to see the parameters of the model. - Use
{{ handler.model.__class__.__name__ }}to see the name of the algorithm being used. - Any other attribute or method of an sklearn estimator can be accessed as
{{ handler.model.<attribute> }}
If left unspecified, MLHandler will render a default template that shows some details of your MLHandler application. The default template for the Titanic problem can be seen here.
Feature Engineering in MLHandler
MLHandler supports feature engineering by allowing users to specify data transformations.
Transformations can be enabled by adding a transform: value to the data parameter in the
MLHandler config, as follows:
mlhandler-transform:
pattern: /$YAMLURL/transform
handler: MLHandler
kwargs:
data:
url: $YAMLPATH/train_data.csv
# transform: is a dotted path to the function that transforms data. It runs:
# data = mymodule.transform_func(data) or data
transform: mymodule.transform_func
Note that the function used to transform the data must accept a dataframe as the first argument, and should return only the transformed dataframe. The transform can also be an expression or pipeline, instead of a function name.
Example: Classify overlapping patterns with logistic regression
Consider the following dataset, containing two classes that are not linearly separable.
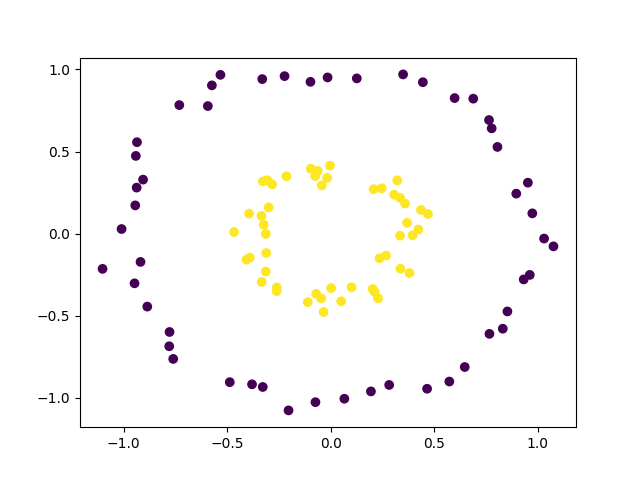
Here is a file containing this dataset. Suppose, we create an MLHandler endpoint using a logistic regression to classify this dataset, as follows:
mlhandler-basiccircles:
pattern: /$YAMLURL/circlebasic
handler: MLHandler
kwargs:
xsrf_cookies: false
data:
url: $YAMLPATH/circles.csv
model:
class: LogisticRegression
target_col: y
Clearly, logistic regression cannot achieve an accuracy of more than 50% on this dataset, since it is only capable of drawing a straight discriminating line through the plot.
But we can transform this data in such a way that the classes become linearly separable. This can be done by writing a transform function as follows:
def transform(df, *args, **kwargs):
df[['X1', 'X2']] = np.exp(-df[['X1', 'X2']].values ** 2)
return df
The dataset transformed thus looks like follows:
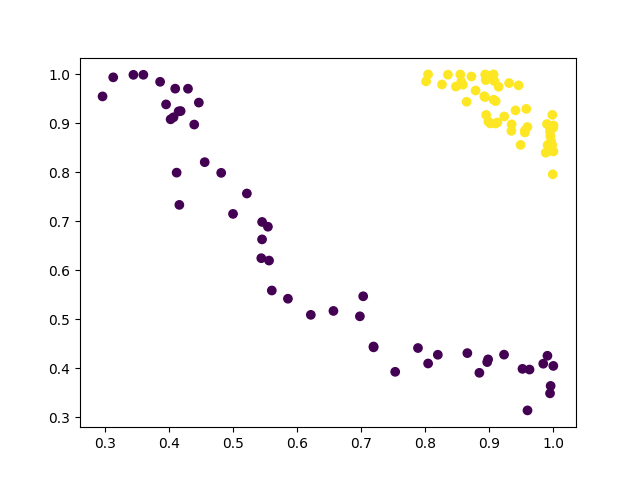
This transformed dataset is now manageable with logistic regression. To add the
transformation to the MLHandler configuration, use the transform: key under
the data: kwarg, as follows:
mlhandler-basiccircles:
pattern: /$YAMLURL/circlebasic
handler: MLHandler
kwargs:
xsrf_cookies: false
data:
url: $YAMLPATH/circles.csv
transform: mymodule.transform # The function used to transform the data
model:
class: LogisticRegression
target_col: y
This will result in the handler transforming the training data, and any incoming dataset for prediction, retraining or scoring.
Time series forecasting
Since v1.78.0, Gramex supports creating forecasting models with MLHandler, via
the SARIMAX algorithm in statsmodels.
To use it, first install stasmodels,
pip install statsmodels
The following YAML spec shows how to setup an MLHandler instance to model and forecast on the German Interest and Inflation Rate dataset. You can download a copy here.
mlhandler-forecast:
pattern: /$YAMLURL/forecast
handler: MLHandler
kwargs:
data:
url: $YAMLPATH/inflation.csv # Inflation dataset
model:
index_col: index # Use index column as timestamps
target_col: R
class: SARIMAX
params:
order:
[7, 1, 0] # Creates ARIMA estimator with (p,d,q)=(7,1,0)
# Add other parameters similarly
Then, to get the forecast for a specific time period, POST the exogenous data and
corresponding timestamps to the /forecast URL.
Sentiment Analysis
v1.80.0 supports sentiment analysis. To set it up, install:
pip install spacy transformers torch datasets
Then use this configuration:
url:
sentiment:
pattern: /sentiment
handler: MLHandler
kwargs:
model:
class: SentimentAnalysis
xsrf_cookies: false
Now visit /sentiment?text=wrong&text=right to see the following output:
["NEGATIVE", "POSITIVE"]
Named Entity Recognition
v1.83.0 supports named entity recognition. To set it up, install:
pip install spacy transformers torch datasets
Then use this configuration:
url:
ner:
pattern: /ner
handler: MLHandler
kwargs:
model:
class: NER
xsrf_cookies: false
Now visit:
/ner?
text=Narendra Modi is the PM of India&
text=Joe Biden is the President of the United States and lives in Washington DC
… to see the following output:
[
{
"text": "Narendra Modi is the PM of India.",
"labels": [
{
"start": 0,
"end": 13,
"label": "PER"
},
{
"start": 27,
"end": 32,
"label": "LOC"
}
]
},
{
"text": "Joe Biden is the President of the United States and lives in Washington DC.",
"labels": [
{
"start": 0,
"end": 9,
"label": "PER"
},
{
"start": 40,
"end": 47,
"label": "LOC"
},
{
"start": 61,
"end": 74,
"label": "LOC"
}
]
}
]
FAQs
How to get the accuracy score of my model?
When trying to see the accuracy of a new dataset against an existing model, use ?_action=score. Specifically, POST the new data to the MLHandler endpoint, with ?_action=score.
# Check the score of a dataset - test.csv - against an existing model
curl -X POST -F "file=@test.csv" 'http://localhost:9988/mlhandler?_action=score'
How to download a model?
Add the ?_download query parameter to the MLHandler endpoint, and perform a
GET. E.g to download the Titanic model included in this tutorial, click
here.
curl -X GET '/mlhandler?_download'
How to download training data?
Add the ?_cache query parameter to the MLHandler endpoint, and perform a GET.
E.g to download the Titanic dataset included in this tutorial, click
here.
curl -X GET '/mlhandler?_cache'
How to append to the training data?
MLHandler supports incremental accumulation of training data. If data is
specified in the YAML confing, it can be appended to, using ?_action=append.
Data can be POSTed in two ways:
-
By including it as JSON in the request body and setting the
Content-Typeheader toapplication/jsonas follows:bash curl -X POST -d @data.json --header "Content-Type: application/json" 'http://localhost:9988/mlhandler?_action=append' -
By POSTing any dataset through a form as a file. (Any
gramex.cache.openformat is supported.)bash curl -X POST -F "file=@data.json" 'http://localhost:9988/mlhandler?_action=append'
Note that when data is being appended, the schema of the appendix has to match the schema of the existing dataset.
How to delete training data?
Send a DELETE request to the MLHandler endpoint with the ?_cache parameter.
E.g:
curl -X DELETE 'http://localhost:9988/mlhandler?_cache'
How to delete the model?
Send a DELETE request to the MLHandler endpoint with the ?_model parameter. E.g:
curl -X DELETE 'http://localhost:9988/mlhandler?_model'
This will cause MLHandler to return an HTTP 404 on subsequent requests to the same
endpoint, until an ?_action=train or ?_action=retrain is requested.