Guide to Anonymising data
We anonymize data to mask confidential information, but preserving the insights that emerge from the data. Here’s a step-by-step process:
- List all columns
- Pick columns action: Drop, Keep or Change. If a column has confidential business results, drop or change it.
- Fill the strategy to anonymize the column. Here are some strategies:
- Categories (text columns with few unique values): Replace values. E.g.:
- State: Replace Indian state names with US state names
- Product: Replace banking products with retail products
- City: Shuffle the cities (i.e. replace values with others in the same list)
- Ordered categories (categories with order): Replace preserving order. E.g.:
- Designation: Replace preserving order (i.e. If Manager -> Boss, Asst Manager -> Asst Boss)
- Hierarchies (related columns): Replace as a group. E.g.:
- State & District: Replace (State, District) with a new (State, District) combination
- IDs (e.g. email ID, mobile, etc). Substitute alphanumerics. Retain symbols.
- Words: Replace sensitive words
- Dates: May be retained
- Integers: Add a random integer. For example,
ROUND(±20% * val * RANDOM()) - Floats: Add a random number. For example,
±20% * value * RANDOM()
- Categories (text columns with few unique values): Replace values. E.g.:
- Reduce data size by sampling. Take a natural subset by applying a filter. Use 2+ values so
that filters show multiple values. E.g:
- instead of world data, use data for any 2+ continents, or 2+ countries
- instead of all products, pick any 2+ categories or 2+ products
- instead of 12 months data, pick 2+ months
This is example of a plan:
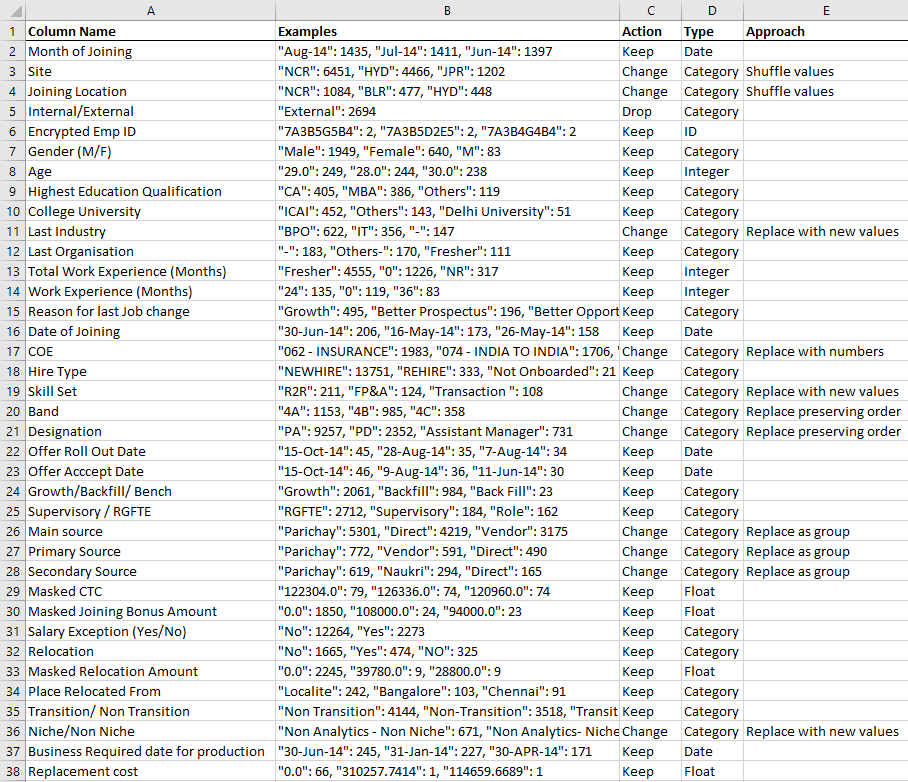
Useful tools: